“And now for our main event! Ladies and gentlemen, in this corner, weighing in at 34% of the cloud infrastructure market, the reigning champion and leader of the public cloud…. Amazon!” Amazon has unparalleled expertise at maximizing scalability and availability for a vast array of customers using a plethora of software products. While Amazon offers software products like DynamoDB, it’s database-as-a-service is only one of their many offerings.
“In the other corner is today’s challenger — young, lightning quick and boasting low-level Big Data expertise… ScyllaDB!” Unlike Amazon, our company focuses exclusively on creating the best database for distributed data solutions.
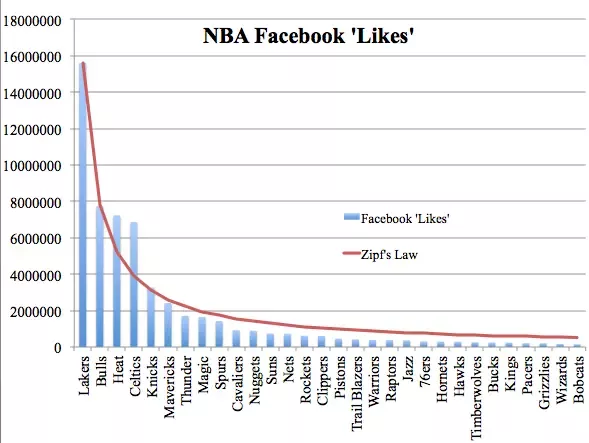
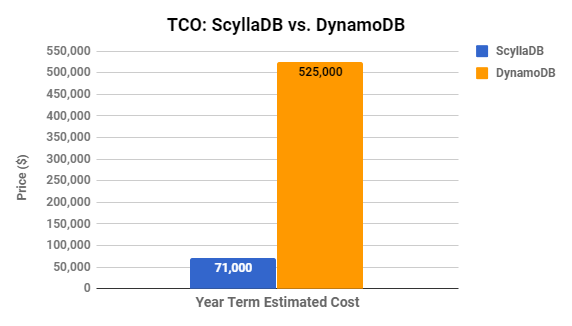
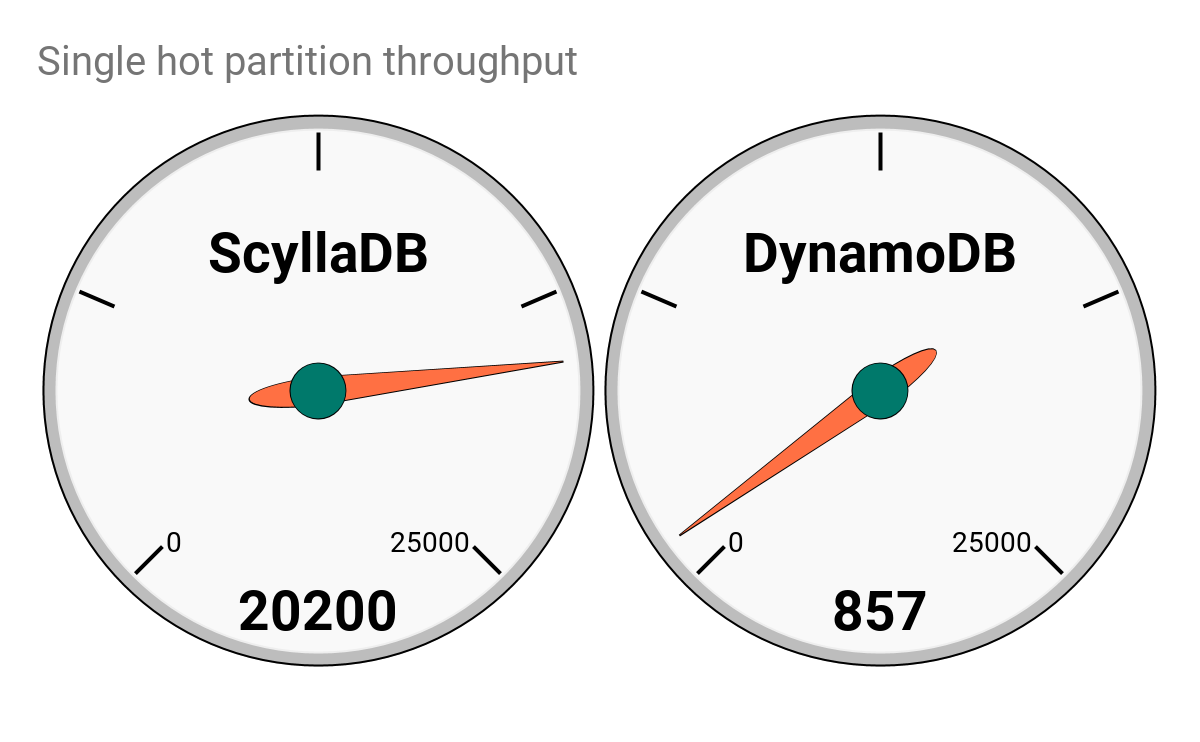
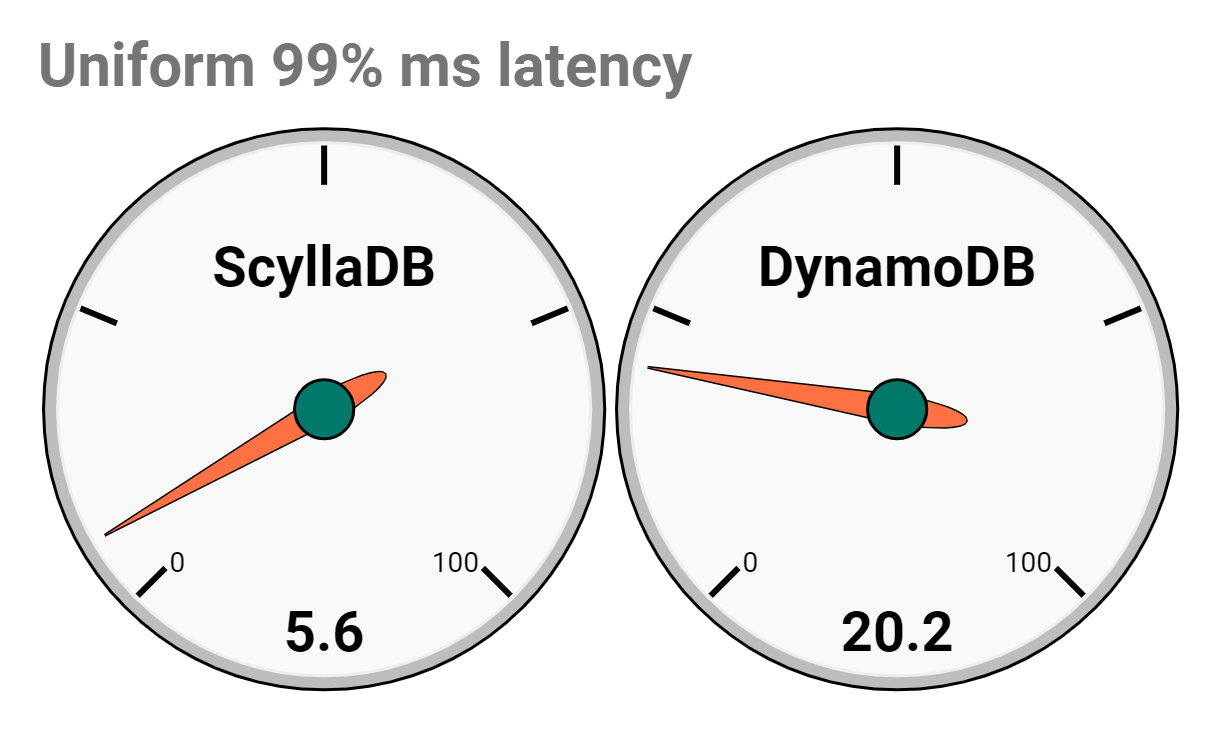
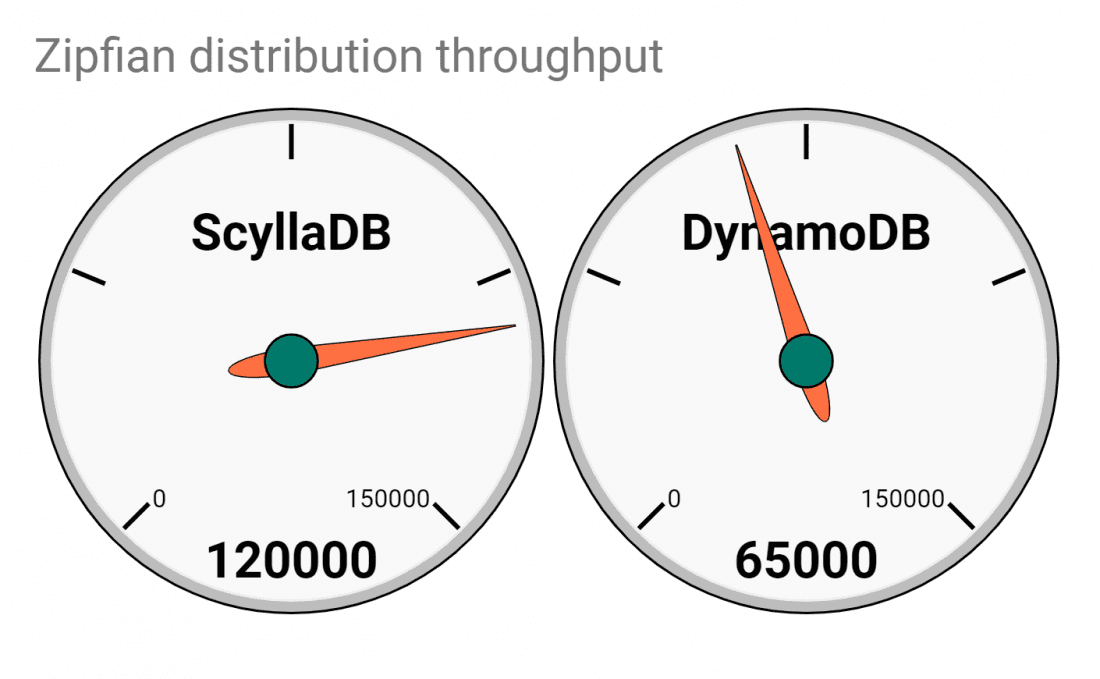
A head-to-head database battle between Scylla and DynamoDB is a real David versus Goliath situation. It’s Rocky Balboa versus Apollo Creed. Is it possible Scylla could deliver an unexpected knockout punch against DynamoDB? [SPOILER ALERT: Our results will show Scylla has 1/4th the latencies and is only 1/7th the cost of DynamoDB — and this is in the most optimized case for Dynamo. Watch closely as things go south for Dynamo in Round 6. Please keep reading to see how diligent we were in creating a fair test case and other surprise outcomes from our benchmark battle royale.]
To be clear, Scylla is not a competitor to AWS at all. Many of our customers deploy Scylla to AWS, we ourselves find it to be an outstanding platform, and on more than one occasion we’ve blogged about its unique bare metal instances. Here’s further validation — our Scylla Cloud service runs on top of AWS. But we do think we might know a bit more about building a real-time big data database, so we limited the scope of this competitive challenge solely to Scylla versus DynamoDB, database-to-database.
Scylla is a drop-in replacement for Cassandra, implemented from scratch in C++. Cassandra itself was a reimplementation of concepts from the Dynamo paper. So, in a way, Scylla is the “granddaughter” of Dynamo. That means this is a family fight, where a younger generation rises to challenge an older one. It was inevitable for us to compare ourselves against our “grandfather,” and perfectly in keeping with the traditions of Greek mythology behind our name.
If you compare Scylla and Dynamo, each has pros and cons, but they share a common class of NoSQL database: Column family with wide rows and tunable consistency. Dynamo and its Google counterpart, Bigtable, were the first movers in this market and opened up the field of massively scalable services — very impressive by all means.
Scylla is much younger opponent, just 4.5 years in age. Though Scylla is modeled on Cassandra, Cassandra was never our end goal, only a starting point. While we stand on the shoulders of giants in terms of existing design, our proven system programing abilities have come heavily into play and led to performance to the level of a million operations per second per server. We recently announced feature parity (minus transactions) with Cassandra, and also our own database-as-a-service offering, Scylla Cloud.
But for now we’ll focus on the question of the day: Can we take on DynamoDB?
Rules of the Game
With our open source roots, our culture forces us to be fair as possible. So we picked a reasonable benchmark scenario that’s supposed to mimic the requirements of a real application and we will judge the two databases from the user perspective. For the benchmark we used Yahoo! Cloud Serving Benchmark (YCSB) since it’s a cross-platform tool and an industry standard. The goal was to meet a Service Level Agreement of 120K operations per second with a 50:50 read/write split (YCSB’s workload A) with a latency under 10ms in the 99% percentile. Each database would provision the minimal amount of resources/money to meet this goal. Each DB should be populated first with 1 billion rows using the default, 10 column schema of YCSB.
We conducted our tests using Amazon DynamoDB and Amazon Web Services EC2 instances as loaders. Scylla also used Amazon Web Services EC2 instances for servers, monitoring tools and the loaders.
These tests were conducted on Scylla Open Source 2.1, which is the code base for Scylla Enterprise 2018.1. Thus performance results for these tests will hold true across both Open Source and Enterprise. However, we use Scylla Enterprise for comparing Total Cost of Ownership
DynamoDB is known to be tricky when the data distribution isn’t uniform, so we selected uniform distribution to test Dynamo within its sweet spot. We set 3 nodes of i3.8xl for Scylla, with replication of 3 and quorum consistency level, loaded the 1 TB dataset (replicated 3 times) and after 2.5 hours it was over, waiting for the test to begin.

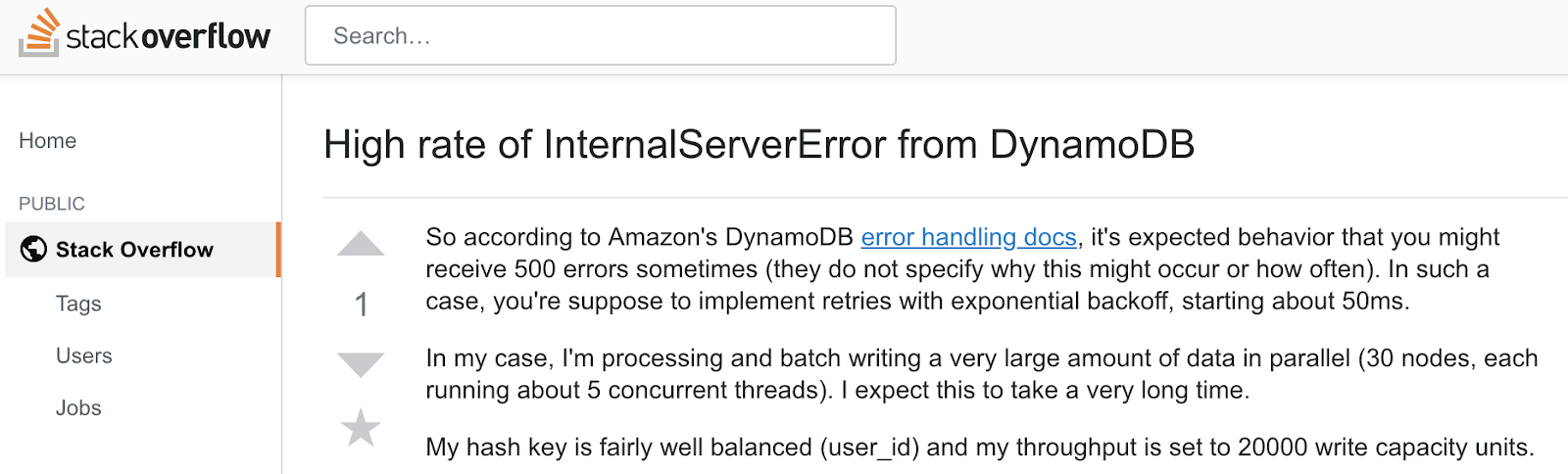
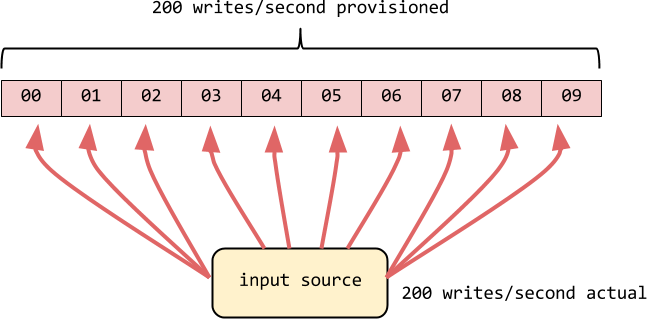
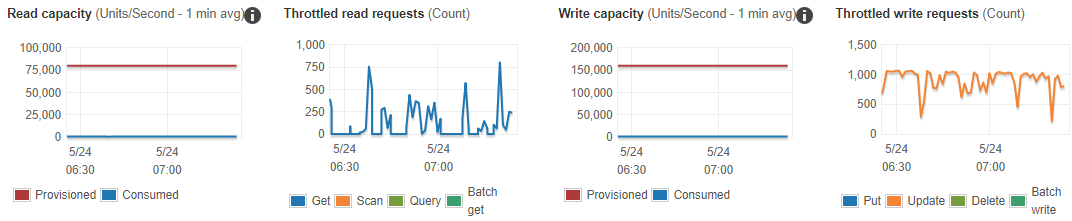
 We hit errors on ~50% of the YCSB threads causing them to die when using ≥50% of write provisioned capacity.
We hit errors on ~50% of the YCSB threads causing them to die when using ≥50% of write provisioned capacity.